Google’s Dremel paper is an interesting read that explains some of the concepts that underlie BigQuery. I am still processing the paper and have noticed a few things about repetition and definition levels that are relevant to the every day use of BigQuery.
Columnar Data and Records
The underlying storage format for BigQuery is columnar. One of the first pieces of advice given to people using BigQuery is to only select the rows that you need.
To demonstrate, this query will process 817 GB of data:
SELECT *
FROM `bigquery-public-data.github_repos.commits`;
Limiting the number of rows does not reduce the amount of data that is processed (this is still 817 GB):
SELECT *
FROM `bigquery-public-data.github_repos.commits`
LIMIT 1000;
In contrast, if you select commiier from this dataset, only 21.7 GB is processed:
SELECT committer
FROM `bigquery-public-data.github_repos.commits`;
This also applies to RECORD fields. This only processes 12.8 GB:
SELECT committer.email
FROM `bigquery-public-data.github_repos.commits`;
When reading about the repetition and definition levels in BigQuery’s data format, I realized that limiting the selection also applies to repeated fields.
In this dataset difference is an array. This query processes 612.7 GB:
SELECT diff
FROM `bigquery-public-data.github_repos.commits`,
UNNEST(difference) AS diff;
The real breakthrough I had was realizing that you can just select a field from the repeated record. This query only processes 1.7 MiB:
SELECT diff.old_repo
FROM `bigquery-public-data.github_repos.commits`,
UNNEST(difference) AS diff;
This could greatly reduce the amount of data you have to process if you are only interested in certain fields of the repeated record. In the above example, by selecting only the old_repo field we process 0.00027777777% of the data that we would have by selecting the entire record.
Record Depth
According to the documentation, the maximum depth of nested repeated fields is 15. I don’t think many people will come up against that limit. Just to double check, this is what happens when you try to create a schema that has too many levels.
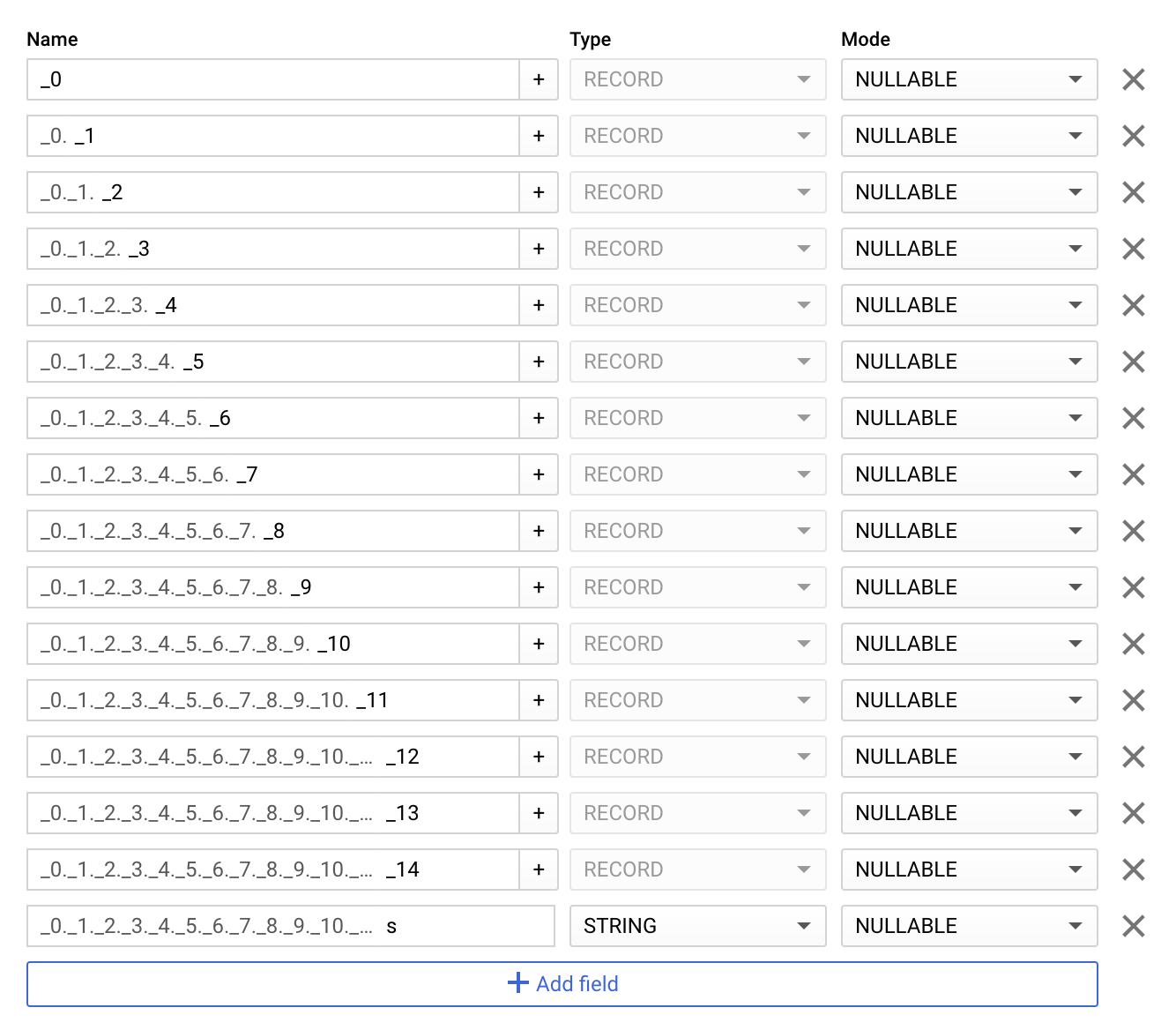
The error message:

The Dremel paper says:
Levels are packed as bit sequences. We only use as many bits as necessary; for example, if the maximum definition level is 3, we use 2 bits per definition level.
I’m assuming the maximum definition level of 15 is to limit this information to a single byte (4 bits for repetition level and 4 bits for definition level).
Further Reading
- How BigQuery actually stores the data. Spoiler alert: it’s complicated and depends on what your data looks like.